連結串列(Linked List)
一種常見的資料結構,利用這個資料結構也能進一步實作出其他的資料結構,例如堆疊(Stack)和佇列(Queue)等。
它的特性是能夠不使用連續的記憶體空間的情況下,能夠保有並使用一份連續的資料;相對來看,陣列則需要使用連續的記憶體空間。
他的的實作方式是每個節點除了記錄資料之外,還使用額外的指標指向下一個節點,將節點以此方式串連起來形成一個連結串列。
由以上的說明可以知道,使用連結串列的優點如下:
不需使用連續記憶體空間,不需事先指定串列大小。
能夠容易的修改指標,插入或移除節點。
但也有缺點如下:
使用額外的記憶體空間紀錄節點指標。
無法快速索引到某個節點,必須迭代搜索。
此資料結構可以實作的操作變化相當多,這裡實作以下幾種操作:
getFirst:取得第一個節點。
getLast:取得最後一個節點。
addFirst:加入節點在最前面。
addLast:加入節點到最後。
addBefore:加入節點在某節點之前。
addAfter:加入節點在某節點之後。
removeFirst:移除第一個節點。
removeLast:移除最後一個節點。
remove:移除某一個節點。
size:取得串列的數目。
連結串列也有許多種類,這邊實作兩種基本的連結串列版本:
單向連結串列(Singly Linked List)
單向連結串列的每個節點只記錄了下一個節點(或者上一個節點),而尾端的節點指向空值。如下圖:

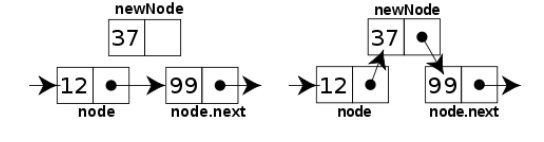
插入新節點示意圖
移除節點示意圖
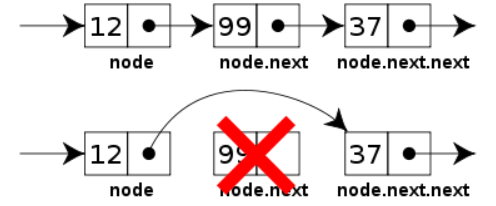
然而我們從上圖中可以看到,刪除節點的時候是刪除指定的節點(node)後面的節點(node.next),而不是刪除節點本身,在程式介面中不是很直覺,例如remove(node),結果被刪除的是node.next。
那為什麼不直接刪除指定節點?因為必須要找到被刪除的節點的前一個節點(node.previous),將他的下一個節點重新指向,而在單向連結串列中沒辦法直接取得上一個節點,除非從頭開始找。
雙向連結串列(Doubly Linked List)
而雙向連結串列則同時記錄了下一個節點和上一個節點,除了尾端節點的下一個節點指向空值外,第一個節點的前一個節點也指向空值。如下圖:

因為多紀錄了上一個節點,所以就能夠解決單向連結串列中所提到的問題。